Python ML in Production - Part 1: FastAPI + Celery with Docker
Building a production-ready project skeleton that allows devs and researchers to focus on the business logic.

Full-Time SW Engineer in the Data Science field. Learning and sharing my journey in Full Stack Development, Entrepreneurship and Financial Freedom
Motivation
Ever found yourself building an API around your brand new ML model browsing your previous projects looking for configuration files, Dockerfiles, docker-compose.yaml, etc? Did it happen that the new microservice-based app you just built has the same product structure and technologies than other apps you built in the past?
Consider your unique product code as a blackbox F that takes an input X and returns an output F(X)=Y. While X, F and Y may be different from project to project, everything that surrounds F and moves X and Y has often a similar structure, if not the same.
For this reason, I believe that in the same way boilerplate extensions prevent web developers from re-writing the same HTML tags over and over again, allowing them to focus on the page content, there can be a way to prevent software engineers like you and me to rewrite the same Dockerfiles, docker-compose.yaml, configurations over and over again, allowing us to focus only on our brand new product.
Goal
As the title suggests, the final goal is to build a portable, generic, production-ready Python API project skeleton that comes with all the microservices packed and configured using the best practices available, allowing devs and researchers to focus only the business logic of their product.
The skeleton aims at automating the following flow:
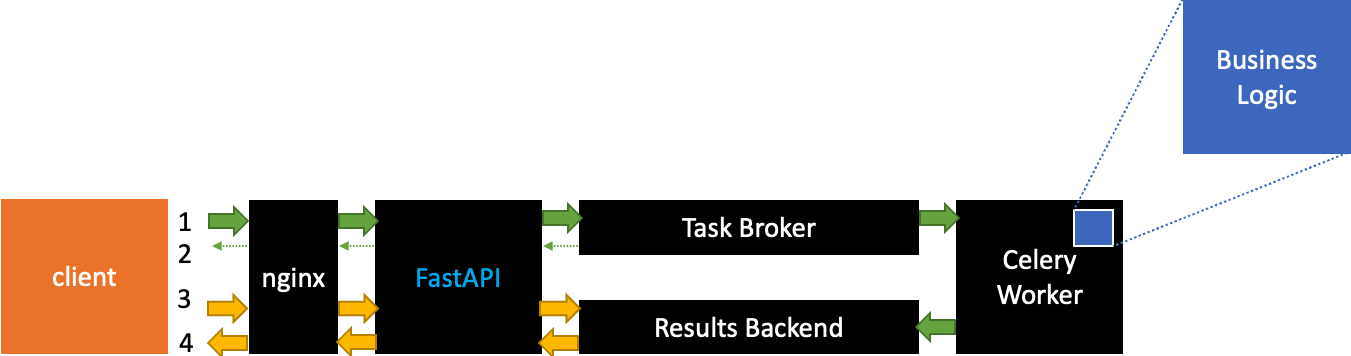
- Client sends a request containing X to the API
- The API replies to the client with a Process ID. By that time the API has added a new job to the Task Broker queue, task that will be executed asynchronously by the first celery worker available, and the results will be saved in the Results Backend together with the Process ID.The client does not have to wait for the task to be executed.
- The client can ask for the current status of the task associated
- Status is returned together with the result, if available
Notice that Business Logic and FastAPI are coloured in blue because they should be the only parts that change from project to project, like the content of the body tag in HTML boilerplates, while all the remaining components in black should not change.
Overview
You can find the whole project in this repository. This specific status of the project has a tag, so that if in the future the repo changes or grows, you have a pin to the version existing at the time or writing.
For the celery and FastAPI configuration I have to give credits to this brilliant post by Jonathan Readshaw, as you will see it inspired and helped me a lot.
For this meta-project I have selected the following technologies:
- FastAPI for the API implementation
- Celery for queuing and executing jobs asynchronously
- RabbitMQ as Celery Queue, or Task Broker
- Redis as Celery Result Backend
- Nginx as web-server/reverse-proxy (not included in this article, will be part of future developments)
The main structure is the following, and it follows the previous blocks schema:
.
├── .env
├── docker-compose.yaml
├── fast-api-celery
│ ├── Dockerfile.base
│ ├── Dockerfile.custom
│ ├── api
│ ├── logic
│ ├── starter.sh
│ └── worker
├── nginx
│ └── Dockerfile
├── rabbit-mq
│ └── Dockerfile
└── redis
└── Dockerfile
Fast-api-celery contains three subfolders that will be discussed throughout the article: logic contains the custom business logic, api contains the API implementation, which details such as routes and models variating together with the logic, and worker contains the Celery Worker implementation. All the three blocks run on the same Docker image.
Docker-compose
.
├── .env
├── docker-compose.yaml
Here we define all the microservices, their names, how they startup and in which order.
version: "3"
services:
_python_image_build:
build:
context: ./fast-api-celery
dockerfile: Dockerfile.base
image: fast-api-celery-base
command: ["echo", "build completed"] # any linux command which directly terminates.
# RESULTS BACKEND
redis:
build: ./redis
container_name: redis-backend
networks:
- production-boilerplate
ports:
- "6379:6379"
# BROKER
rabbitmq:
build: ./rabbit-mq
container_name: rabbitmq-broker
networks:
- production-boilerplate
ports:
- "5672:5672"
- "15672:15672"
# WORKER
celery:
build:
context: ./fast-api-celery
dockerfile: Dockerfile.custom
image: fast-api-celery-custom
container_name: celery-worker
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
- CELERY_QUEUE=${CELERY_QUEUE}
command: ./starter.sh --target worker
depends_on:
- redis
- rabbitmq
# MONITOR
flower:
image: fast-api-celery-custom
container_name: celery-flower
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
command: ./starter.sh --target flower
ports:
- "5555:5555"
depends_on:
- redis
- rabbitmq
- celery
# API
fastapi:
image: fast-api-celery-custom
container_name: fastapi
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
command: ./starter.sh --target fastapi
ports:
- "8000:80"
depends_on:
- redis
- rabbitmq
- celery
networks:
production-boilerplate:
driver: bridge
- _python_image_build is a fake service that I use to build the fast-api-celery-base image that will then be used by FastAPI and Celery
- redis, rabbitmq are the services on which Celery will rely for task queuing and result storage, they don't need particular configurations
- celery makes use of the fast-api-celery-base image built by _python_image_build service. It needs to know where the broker and backend service are, and it starts by booting the celery service
- flower is actually a 'bonus' service, not mentioned before. It's like celery but instead of booting celery service it boots the flower service, which monitors celery workers and tasks status
- fastapi is the same as celery and flower but at its startup it's told to boot the API service
Since we define a docker network with all the microservices inside, we can link redis and rabbitmq with their name defined in the docker-compose. Here is the .env file:
CELERY_BROKER_URL=amqp://guest@rabbitmq//
CELERY_BACKEND_URL=redis://redis:6379/0
Our blackbox F
.
├── fast-api-celery
│ ├── logic
│ │ ├── __init__.py
│ │ └── model.py
fast-api-celery/logic is supposed to be the only place where we put the business logic of our application. The focus of this post is not on the model we want to serve, model.py (our F) for this example looks like the following:
class FakeModel:
def __init__(self):
self.m = 7.0
self.q = 0.5
def predict(self, x: float) -> float:
y = self.m * x + self.q
return y
The only thing we care about is that at its initialisation it loads some "weights", and that it exposes a predict method which takes an input X and returns an output Y, as any ML model would do regardless of its task.
Now let's see how to serve the model!
Celery Broker and Backend
.
├── rabbit-mq
│ └── Dockerfile
└── redis
└── Dockerfile
RabbitMQ and Redis just need to be up and running, for the moment we do not need particular configurations. We will then tell Celery to work with these two containers as Broker and Backend respectively.
Dockerfile for RabbitMQ:
FROM rabbitmq:3.10-management
CMD ["rabbitmq-server"]
Dockerfile for Redis:
FROM redis
CMD ["redis-server"]
API and Worker
The API must be able to import dependencies from the worker, such as its tasks and the AsynchResult method for retrieving job results. At the same time, the worker must be able to import dependencies from our custom logic package so that all the worker threads will be able to execute its code. For this reason, I build a single image with an environment containing all the dependencies for the API, Celery and the Model.
Dockerfiles
.
├── fast-api-celery
│ ├── Dockerfile.base
│ ├── Dockerfile.custom
I recently wrote another blog post on how to build an optimised docker image if using Python and Poetry as package manager. From that post, I wrote the following Dockerfiles.
Base
Dockerfile.base
#
# Build image
#
FROM python:3.9-slim-bullseye AS builder
WORKDIR /app
COPY . .
RUN apt update -y && apt upgrade -y && apt install curl -y
RUN curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python -
RUN $HOME/.poetry/bin/poetry config virtualenvs.create false
RUN $HOME/.poetry/bin/poetry install --no-dev
RUN $HOME/.poetry/bin/poetry export -f requirements.txt >> requirements.txt
#
# Prod image
#
FROM python:3.9-slim-bullseye AS runtime
WORKDIR /app
COPY --from=builder /app/requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
With this Dockerfile we create a new base image called fast-api-celery-base, that will be used as starting point for all the three services mentioned above.
Custom
#
# Customizations
#
FROM fast-api-celery-base
WORKDIR /app
RUN mkdir api worker logic
COPY api ./api
COPY worker ./worker
COPY logic ./logic
COPY starter.sh .
RUN chmod +x starter.sh
ENTRYPOINT ["/bin/bash"]
In this Dockerfile.custom I just copy the three folders api, worker, and logic. Note that the two dockerfiles above are splitted to speed up development: Building the base environment takes minutes and should be done only if dependencies change, while creating the final image (code changes) takes only a couple of seconds.
Celery
.
├── fast-api-celery
│ └── worker
│ ├── __init__.py
│ ├── celery.py
│ └── tasks.py
As mentioned above, this part takes inspiration to this post by Jonathan Readshaw. I only had to add the "logic" string in the include parameter list so that every worker has its logic package available when running.
Worker - celery.py
from celery import Celery
import os
worker = Celery(
"proj",
backend=os.getenv("CELERY_BACKEND_URL"),
broker=os.getenv("CELERY_BROKER_URL"),
include=["worker.tasks", "logic"],
)
# Optional configuration, see the application user guide.
worker.conf.update(
result_expires=3600,
)
if __name__ == "__main__":
worker.start()
Task - task.py
import importlib
import sys
import logging
from celery import Task
from .celery import worker
class PredictTask(Task):
"""
Abstraction of Celery's Task class to support loading ML model.
"""
abstract = True
def __init__(self):
super().__init__()
self.model = None
def __call__(self, *args, **kwargs):
"""
Load model on first call (i.e. first task processed)
Avoids the need to load model on each task request
"""
if not self.model:
logging.info("Loading Model...")
sys.path.append("..")
module_import = importlib.import_module(self.path[0])
model_obj = getattr(module_import, self.path[1])
self.model = model_obj()
logging.info("Model loaded")
return self.run(*args, **kwargs)
@worker.task(
ignore_result=False,
bind=True,
base=PredictTask,
path=("logic.model", "FakeModel"),
name="{}.{}".format(__name__, "Fake"),
)
def predict(self, x):
return self.model.predict(x)
FastAPI
.
├── api
│ ├── __init__.py
│ ├── main.py
│ └── models.py
Models - models.py
Here we define the form of our X and Y. FastAPI will use them to validate user's input
from pydantic import BaseModel
class TaskTicket(BaseModel):
"""ID and status for the async tasks"""
task_id: str
status: str
# X
class ModelInput(BaseModel):
"""Model features as input for prediction"""
x: float
# Y
class ModelPrediction(BaseModel):
"""Final result"""
task_id: str
status: str
result: float
Endpoints - main.py
Here we are defining two endpoints:
- [POST] /fakemodel/predict to create a new task and get the Task ID
- [GET] /fakemodel/result/{task_id} to get its current status
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from celery.result import AsyncResult
from worker.tasks import predict
from .models import ModelInput, TaskTicket, ModelPrediction
app = FastAPI()
@app.post("/fakemodel/predict", response_model=TaskTicket, status_code=202)
async def schedule_prediction(model_input: ModelInput):
"""Create celery prediction task. Return task_id to client in order to retrieve result"""
task_id = predict.delay(dict(model_input).get("x"))
return {"task_id": str(task_id), "status": "Processing"}
@app.get(
"/fakemodel/result/{task_id}",
response_model=ModelPrediction,
status_code=200,
responses={202: {"model": TaskTicket, "description": "Accepted: Not Ready"}},
)
async def get_prediction_result(task_id):
"""Fetch result for given task_id"""
task = AsyncResult(task_id)
if not task.ready():
print(app.url_path_for("schedule_prediction"))
return JSONResponse(
status_code=202, content={"task_id": str(task_id), "status": "Processing"}
)
result = task.get()
return {"task_id": task_id, "status": "Success", "result": str(result)}
Starter
Since Celery, Flower and FastAPI have all the same image and the same files, we need to differentiate their startup command. With this utility script we use the --target parameter to control commands from the docker-compose file.
#!/bin/bash
while [ $# -gt 0 ] ; do
case $1 in
-t | --target) W="$2" ;;
esac
shift
done
case $W in
worker) celery --broker ${CELERY_BROKER_URL} --result-backend ${CELERY_BACKEND_URL} -A worker.celery worker --loglevel=INFO;;
flower) celery --broker ${CELERY_BROKER_URL} --result-backend ${CELERY_BACKEND_URL} -A worker.celery flower;;
fastapi) uvicorn api.main:app --host 0.0.0.0 --port 80;;
esac
Testing the application
First build everything from the base folder:
docker-compose build
then run the app!
docker-compose up
What I really liked about FastAPI is that it comes with Swagger with no configuration or action needed by the developer. Head to localhost:8000/docs
"Try out" the POST endpoint first:
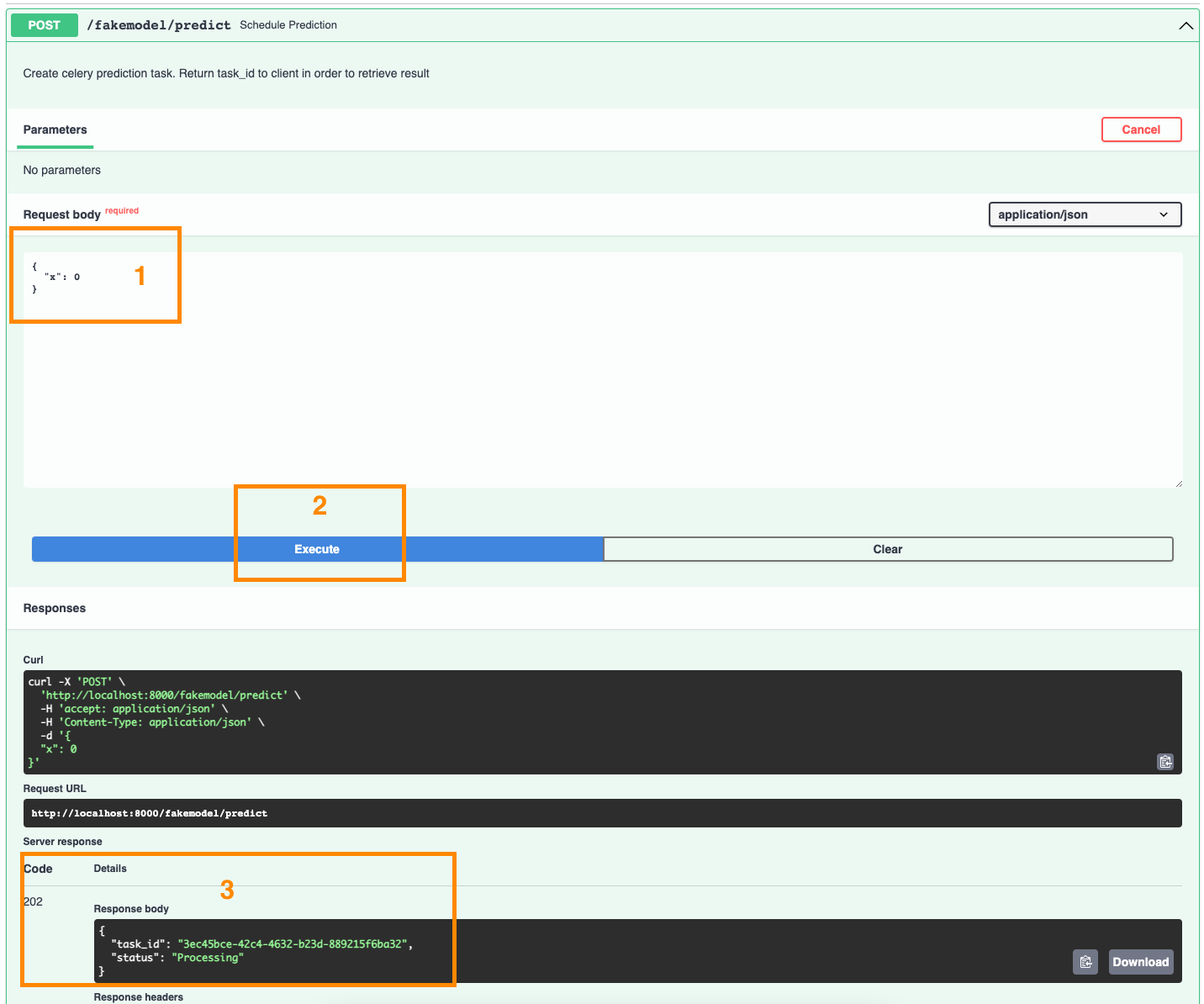
The API replied to us that the prediction we asked for is now processing and its ID is 3ec45bce-42c4-4632-b23d-889215f6ba32
Now we can ask for the status of 3ec45bce-42c4-4632-b23d-889215f6ba32 to the other endpoint:
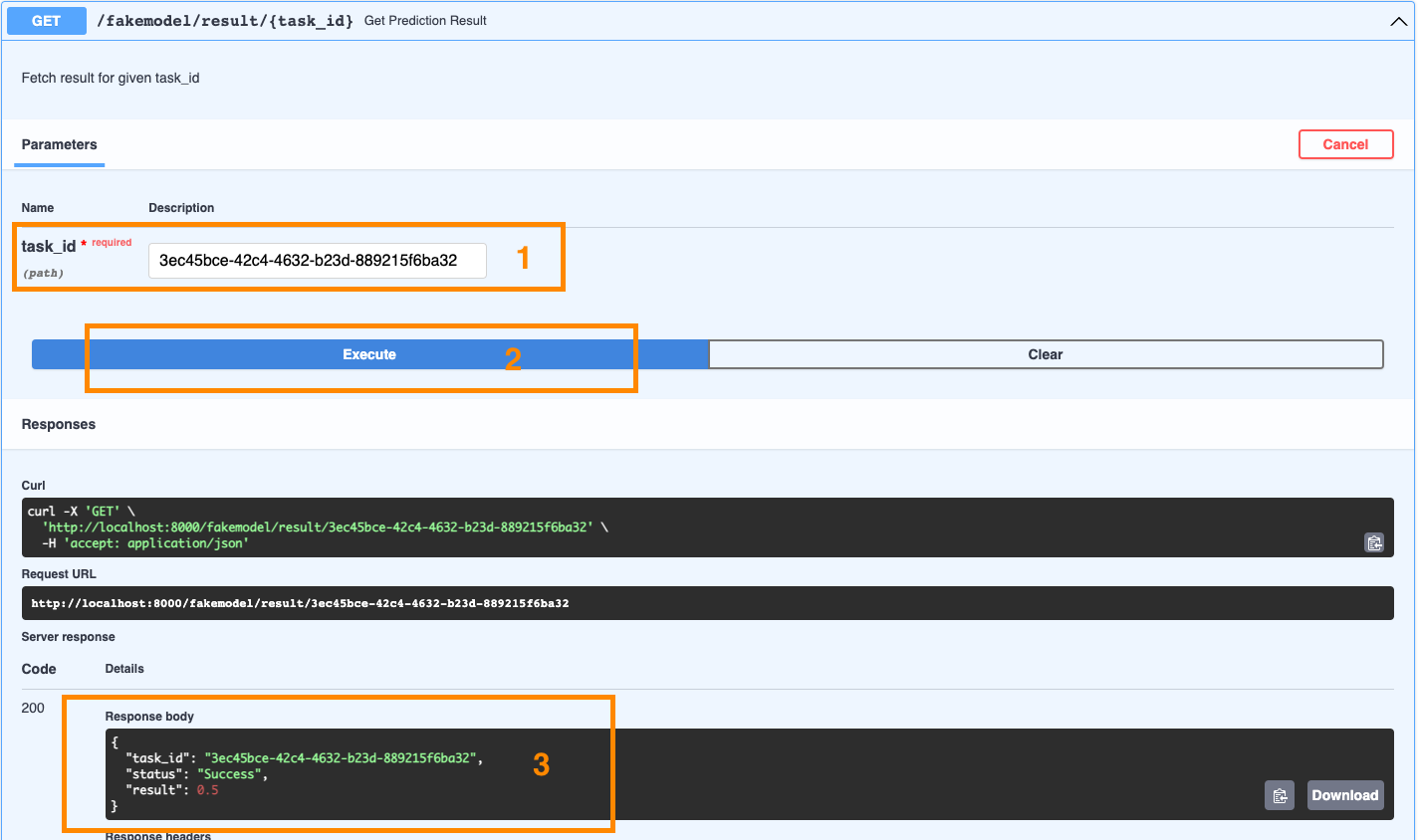
The response contain the Task ID we requested, the status (Success) and the final result of our model's prediction.
Next steps
In the next weeks I'll be exploring the best practices for an optimal and secure use of
- Nginx
- Automated unit and integration test
- Application of the skeleton with a real world example (an actual ML model)
then to close the DevOps circle, further steps could include also:
- CI/CD pipelines
- Cloud integration
- Kubernetes
Wrap-Up
This was a "quick" overview of the elements composing a first version of project skeleton that provides a working asynchronous microservice structure, allowing the developer using it to serve any python logic by modifying only:
- Logic folder (our blackbox F)
- FastAPI endpoints and models (our X and Y)
Thank you for reading this far! I would love to hear your thoughts, suggestions and questions in the comment section below.
Cheers
Denis
